LLM/RAG Kaggle Development Assistant
An on-premises, domain-specific AI assistant for Kaggle (tested on binary disaster-tweet classification), combining LLM, an n8n workflow engine, and Qdrant-backed Retrieval-Augmented Generation (RAG).
Deploy via containerized starter kit.
Needs high end GPU support or patience.
Initial chat should contain guidelines on what to to produce and the challenge guidelines.
Features
- Coding Assistance
• "Real"-time Python code recommendations, debugging help, and data-science best practices
• Multi-turn conversational context
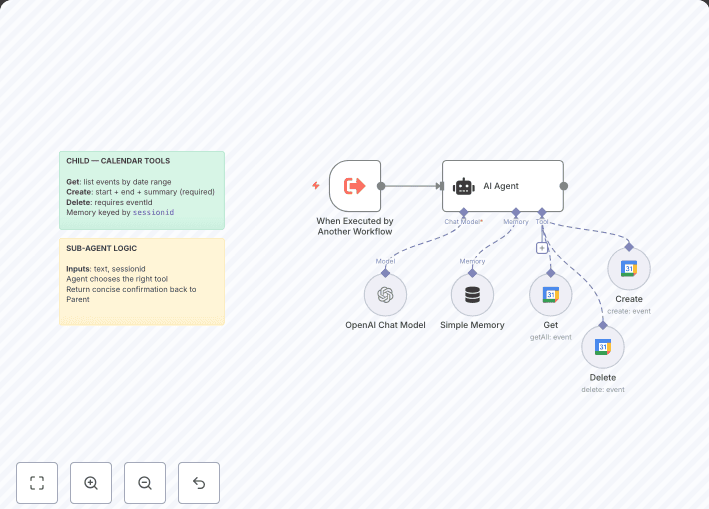
- Workflow Automation
• n8n orchestration for LLM calls, document ingestion, and external API integrations
- Retrieval-Augmented Generation (RAG)
• Qdrant vector-database for competition-specific document lookup
• On-demand retrieval of Kaggle competition guidelines, tutorials, and notebooks after convertion to HTML and ingestion into RAG
- entirly On-Premises for Privacy
• Locally hosted LLM (via Ollama) – no external code or data transfer
ALIENTELLIGENCE/contentsummarizer:latest for summarizing
qwen3:8b for chat and coding
mxbai-embed-large:latest for embedding
• GPU acceleration required
Based on:
https://n8n.io/workflows/2339 breakdown documents into study notes using templating mistralai and qdrant/