Researchers and academic institutions need efficient ways to process and analyze large volumes of research papers and academic documents, including scanned PDFs and image-based materials (JPG, PNG). Manual review of academic literature is time-consuming and makes it difficult to identify trends, track citations, and synthesize findings across multiple papers. This workflow automates the extraction and analysis of research papers and scanned documents using OCR technology, creating a searchable knowledge base of academic insights from both digital and image-based sources.
Research institutions, university libraries, R&D departments, academic researchers, literature review teams, and organizations tracking scientific developments in their field.
Literature reviews require reading hundreds of papers to identify relevant findings and methodologies. This template automates the extraction of key information from research papers, including methodologies, findings, and citations. It builds a searchable database that helps researchers quickly find relevant studies and identify research gaps.
Setup Instructions:
Key Features:
Customization Options:
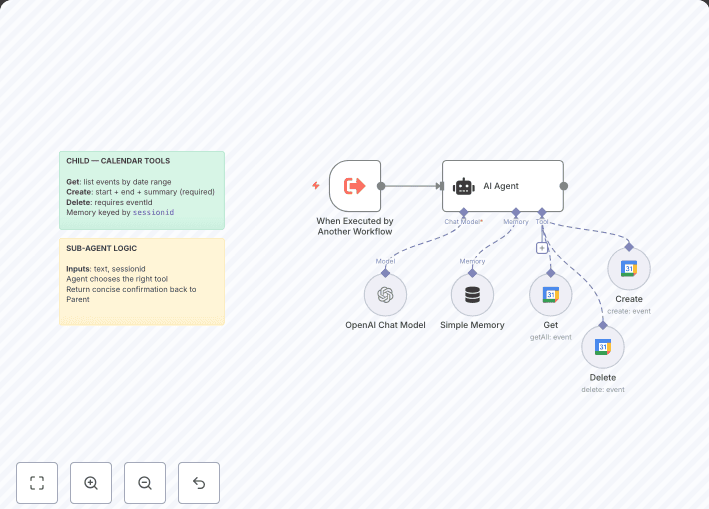
Implementation Details:
The workflow uses PDF Vector's academic features to understand research paper structure and extract meaningful insights. It processes papers from various sources, identifies key contributions, and creates structured summaries. The system tracks citations to measure impact and identifies emerging research trends by analyzing multiple papers in a field.
Note: This workflow uses the PDF Vector community node. Make sure to install it from the n8n community nodes collection before using this template.