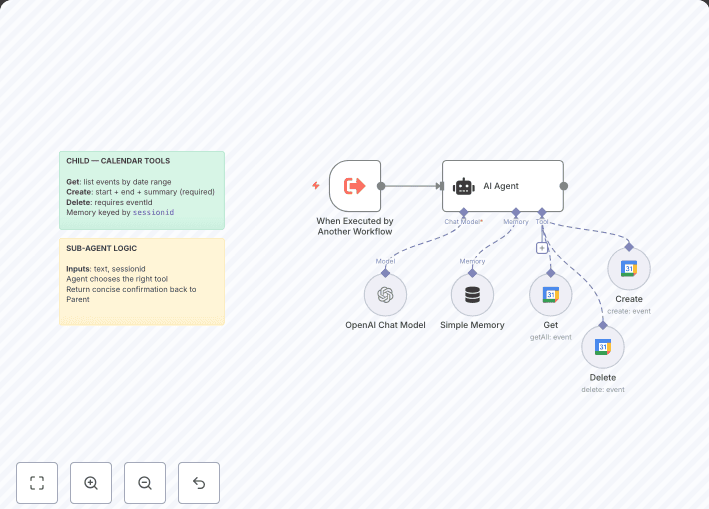
Ingest PDF files from S3, extract text, chunk, embed with OpenAI embeddings, and index into a Qdrant collection with metadata.
Provide a chat entry point that uses an Agent with OpenAI to retrieve from the same Qdrant collection as a tool and answer proposal knowledge questions.
What it does
Lists objects in an S3 bucket, loops through keys, downloads each file, and extracts text from PDFs.
Chunks text and loads it into Qdrant with metadata for retrieval.
Exposes a chat trigger wired to an Agent using an OpenAI chat model.
Adds a retrieve as tool Qdrant node so the Agent can ground answers in the indexed corpus.
Why it is useful
Simple pattern for building a proposal or knowledge base from PDFs stored in S3.
End to end path from ingestion to retrieval augmented answers.
Easy to swap models or collections, and to extend with more tools.
Setup notes
Attach your own AWS credentials to the two S3 nodes and set your bucket name.
Attach your Qdrant credentials to both Qdrant nodes and set your collection.
Attach your OpenAI credentials to the embedding and chat nodes.
The sanitized template uses placeholders for bucket and collection names.